
 Introduction:
Introduction:
GiMeSpace Mega AI predictor is a program that is using past historical data to predict future data. Obvious applications can be predicting stock market shares and any other hard to predict data streams. But also for more simple data sets this program provides superiour learning capacity.
It is using highly optimized techniques that automatically adapt to the data that is being used. The techniques are coming from the Artificial Intelligence, Neural Networks and Machine Learning science and is used in such a way that maximum learning capacity is provided for hard to predict data.
The program is highly optimized for the latest x64 Windows computers. It supports up to 2048 parallel CPU cores/threads and up to 16TB of virtual memory.
The more memory and computing power you have available for this program the more effective this program will predict future data.
Since it is recommended to use massive amounts of memory, the speed of the calculations are likely limited by the access speed of you memory. For extreme projects you might want to invest in the latest high bandwidth RAM and processors that are able to access this RAM at maximum speed.
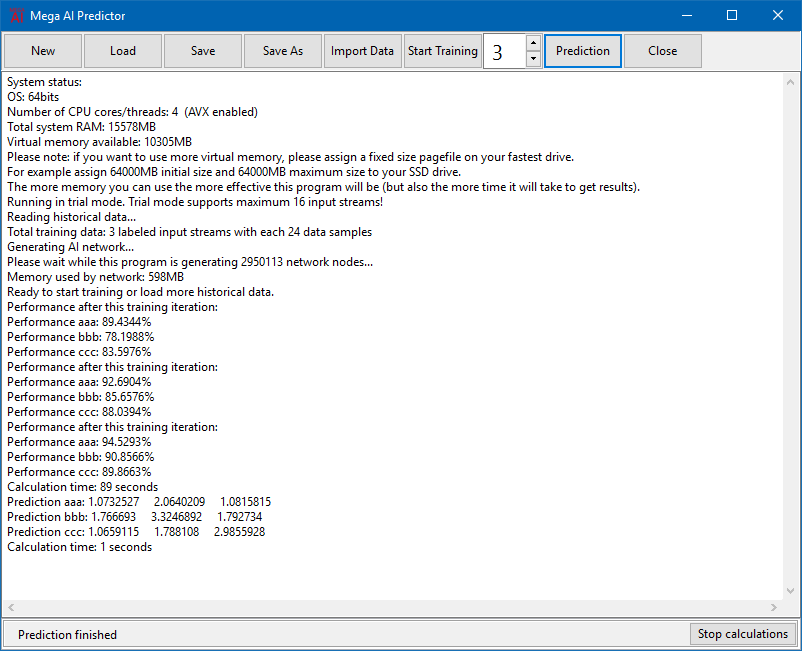
Using this program:
This program will only run on 64bit windows!
Although the logic behind this program is highly complex, this program is actually very straight forward and easy to use.
When you start the program you will see the main text screen giving you all the information you need. And 8 buttons on top that perform all the tasks that are needed.
On the bottom right is a button that can be used to interrupt calculations if you need to interrupt the program. You will have to start the calculations again at a later time.
The first button on top will create a new project.
First you will be asked to specify the input data format. Meta stock 7 file format is supported but also other standard text format data files like csv etc. Values can be separated by spaces, commas or other characters. Data can be presented in horizontal or vertical format. Also there is an option to sort data on a time label if that is present. Please note that this is an alphanumeric sort so data should have time labels like 01, 02, …. 09, 10, 11 and not like 1, 2, … 9, 10, 11. Meta stock data has time labels like 20160113 etc so sorting will work correctly.
Next you will be asked to select a file that contains the first data for all the input streams you want to predict or use. The predicting network will be created according to the number of input streams of the first file. So it will not be possible to add in the future additional input streams! At the moment the program has a limit of 65536 input streams. This limit can be lifted if needed.
Next you will be asked to allocated memory to be used for the predicting network. Unless you have a very simple problem space, it is recommended to use all the memory you have available.
You can also allocated more virtual memory on a fast Solid State Disk by making a fixed size page file on that drive. The initial size of this page file is the size that will specify how much virtual memory is available for this program. Please note that the access to an SSD is still much slower than your RAM and although you will have better prediction results, the learning time will be much longer!
The program will now generate the prediction network, this can take a lot of time to generate!
Once a project is generated you can save it and load it again just like expected.
You can also choose to import more data. For example if you try to predict stock data you might want to import the latest stock data every day. It’s important to note that new data files cannot contain more input data streams than the one you used in the beginning to create the project!
The next step is to allow the program to learn how to predict the data. There is a spin edit that can be used to select the number of training iterations to execute at a time. You can interrupt this training at any time, but it’s important to know that before you can do any predictions you need to complete at least one full training iteration. The more training iterations you do the better your project will perform. After each training iteration the program will specify how successful it can predict the current data. A score of 50% means learning has been unsuccessful (the program is wrong half of the time). Maximum success will be with a score of 100%. But with real world data this will be of course very rare. In general scores of 95% and higher are useful predictions. But this also depends on how accurate you need the predictions to be.
After successful learning you can start to predict future data. The same spin edit can be used to specify the number of prediction iterations.
For each input stream a list of successive data predictions will be produced.
Brief introduction to stock prediction:
For stock predictions it is recommended to get as much data in meta stock 7 format as possible. A few years of daily data is good (not minute to minute, that is too much data)
There are 3 factors that will increase the accuracy of your predictions:
1 the more historical data you have to better it can learn predictions
2 the more memory you dedicate the better the predictions will be
3 the more you train the network the better your predictions will be.
In demo mode you will only be able to import up to 16 different stock data streams at a time. But even in purchased mode it is good to find out what stocks are relevant. If you only what to predict one kind of stock it is still good to also import data from other stocks that are known to have some kind of correlation. Also oil and gold prices are known to have some influence on stock prices.
Stock prediction is a time consuming business. In demo mode it is recommended to load 16 different stock data streams. In unlocked mode it's recommended to load up to 50 relevant data streams,
To get a good dataset it's recommended to get the last 5 years of data.
Since stock correlations are highly complex you need to use all the memory that is available. However if you are using a pagefile for extra virtual memory then the calculations will be a lot slower unless you have an very fast ssd drive.
Recommended is a system with at least 16 cores and 64GB of ram. Expect to train the network for at least a week continues in the beginning. Of course this depends on the speed of your system. Prediction rates need to hit at least 90% to be useful and have a relevant advantage to other traders.
After that you can add daily the latest daily data and run the training again for a few hours a day to optimize for the new data and predict the stock rates for tomorrow or the rest of the week.
Specific solutions.
GiMeSpace is specialized in unsupervised automatic learning solutions. Data prediction is just one of our specialities. Also discrete problems where a program needs to learn from actions being taken can be effectively learned by our techniques. Email gimespace@gimespace.com if you need a specific learning solution.
Disclaimer.
Although this program is designed to provide maximum learning capability for the data that is presented to it, no guarantees are made about the accuracy of its predictions. Using the predictions from this program is your own responsibility. And GiMeSpace recommends that you use the predictions with your own common sense. Under no circumstances will GiMeSpace be ever responsible for any damages or loses caused by using the predictions from this program.








